Recently, Li Feifei’s Vision Lab at Stanford University published a paper Referring Relationships to be introduced in CVPR 2018. The main issue of this paper is to give a network of entities in an image, so that The AI ​​quickly locates the object to which a subject corresponds, or the object to which an object corresponds.

Images are not just collections of objects, each image represents a network of interconnected relationships. The relationships between entities are semantically meaningful and can help observers distinguish between instances of entities. For example, in the image of a football game, there may be many people present, but everyone is involved in different relationships: one is playing football and the other is a goalkeeper.
In this article, we have formulated the task of using these "reference relationships" to eliminate ambiguity among entities of the same category. We introduce an iterative model that will locate two entities in the referential relationship and restrict each other. We use modeling predicates to establish loop conditions between entities in a relationship. These predicates connect entities and divert attention from one entity to another.
We have proved that our model is not only better than existing methods implemented on three datasets -- CLEVR, VRD, and Visual Genome -- but it also produces visually meaningful predicate transformations that can be interpreted as An example of a network. Finally, we show that we model predicates as attention transformations, and we can even locate entities without their categories, so that the model finds completely invisible categories.
▌ Referential relationship tasks
Alleged expressions can help us identify and locate entities in our daily communications. For example, we can point out "kickers" to distinguish "goals" (Figure 1). In these examples, we can distinguish the two people based on their relationship with other entities. When one person shoots, the other person holds the door. The ultimate goal is to build a computational model to identify what other people refer to.
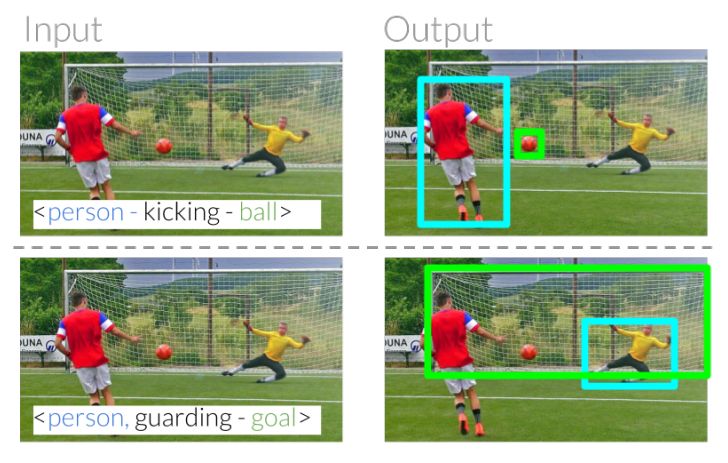
Figure 1: Referential relationships eliminate ambiguity between instances of the same class by using relative relationships between entities. Given this relationship, this task requires our model to correctly identify the kicker in the image by understanding the predicate.

â–Œreferential relational model
Our goal is to eliminate the entity ambiguity in the image by using the input referential relationship to locate the entity that refers to the relationship. Formally speaking, the input is an image I with an alleged relationship, R = , which are the subject, the predicate and the object category, respectively. It is expected that this model can locate subjects and objects.
â–ŒModel design

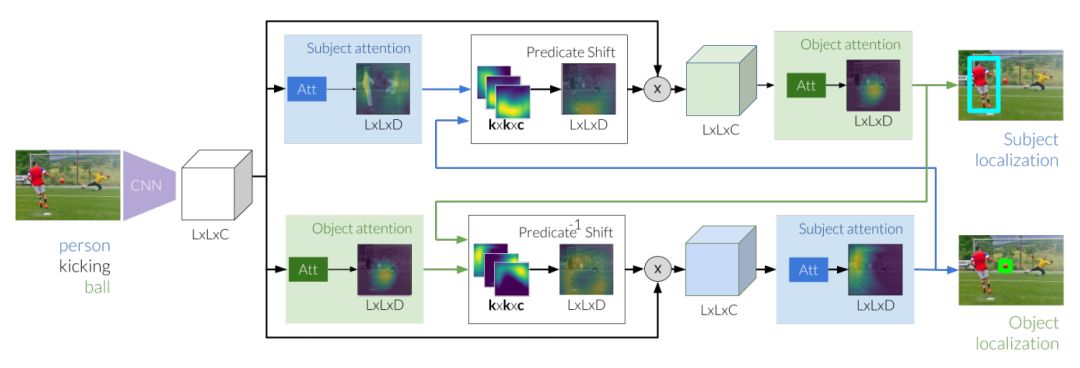
Figure 2: The reasoning for referential relationships first extracts image features, which is the basis for generating subjects and objects. Next, these valuations can be used to perform diversions of attention, using attention from the subject to the predicate we expect the location of the object. While refining the new valuation of the object, we modify the image feature by focusing on the conversion area. At the same time, we studied the reverse shift from the initial object to the subject. The two entities are ultimately located by the two predictive shift modules that iteratively pass messages between the subject and the object.
Experiment
We performed experimental operations by evaluating model performance across reference relationships across three data sets, each of which provided a unique set of features to supplement our experiments. Next, we evaluate how to improve the model in the absence of one of the entities in the input referential relationship. Finally, the experiment was ended by showing how the model was modularized and used for scene-view attention scanning.
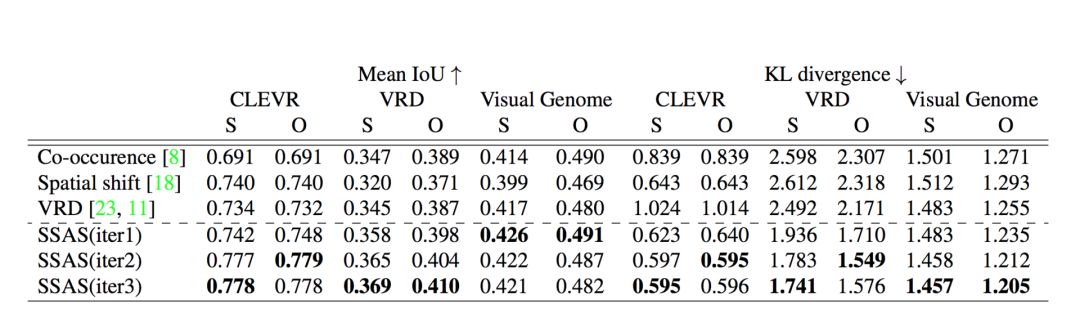
The following are our evaluation results on CLEVR, VRD and Visual Genome. We have marked the disagreement between Mean IoU and KL on the subject and object positioning respectively:
Missing entity referential relationship results under three test conditions:
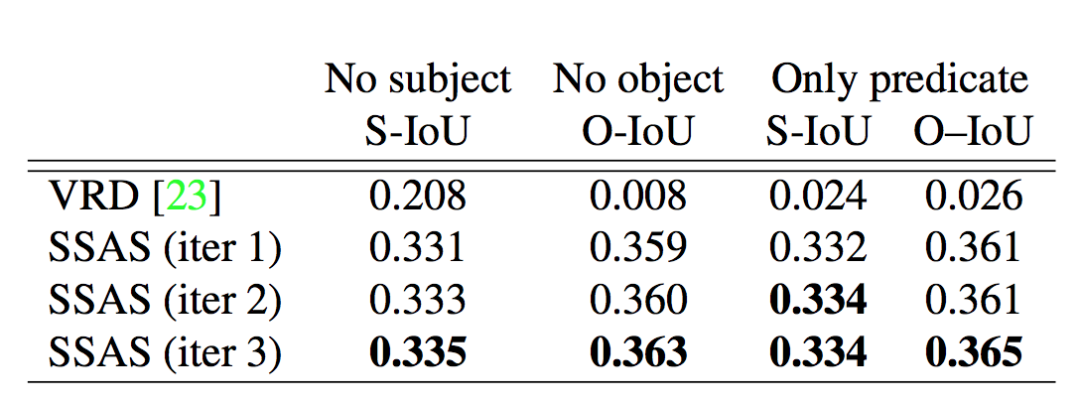
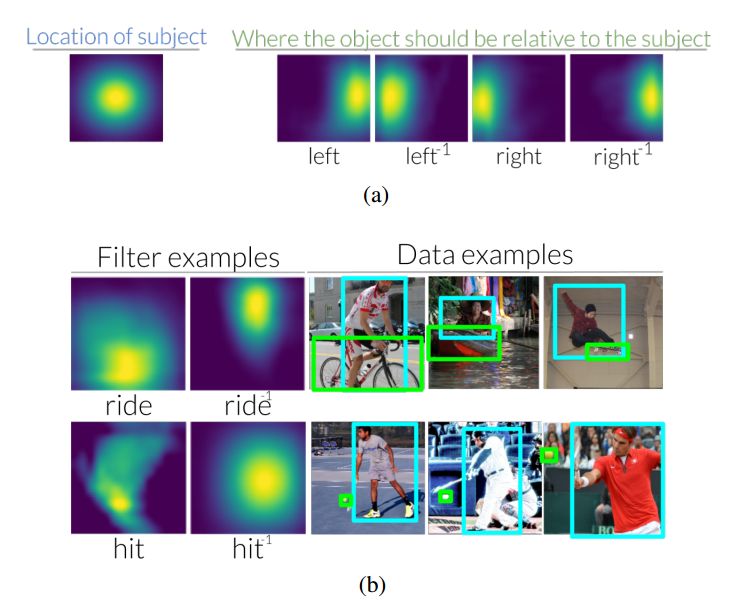
Figure 3: (a) With respect to subjects in an image, when using relationships to find objects, the left predicate shifts attention to the right. In contrast, when an object is used to find a subject, the inverse predicate on the left shifts attention to the left. In the auxiliary material, we visualized the predicate and inverse predicate transformations of 70 VRDs, 6 CLEVRs, and 70 Visual Genomes. (b) We also see that these transformations are intuitive when looking at the data sets used to understand them. .

Figure 4: This is an example of how the attention shift of the CLEVR and Visual Genome data sets spans multiple iterations. At the first iteration, the model only receives entity information that tries to find and try to locate all instances in these categories. In later iterations, we see that the predicate converts attention, which allows our model to disambiguate between different instances of the same class.

Figure 5: We can decompose our model into its attention and transformation modules and stack them up as nodes of the scene graph. Here, we demonstrate how to use the model to start from a node (mobile phone) and use a referential relationship to connect the nodes through the scene graph and locate the entity in the phrase <person wearing a jacket next to the person holding the phone>. The second example is about the entity in front of a table at the right of the person wearing a hat.
Conclusion

Shenzhen Konchang Electronic Technology Co.,Ltd , https://www.konchang.com