The OMAP platform provides the perfect solution for developing voice applications for personal handheld devices. This low-power OMAP architecture combines DSP signal processing for voice with the general system performance of a RISC processor. An open software architecture was designed to encourage the development of complementary applications such as speech engines, voice applications and multimedia. Development support, including speech recognizers and prototyping applications, helps developers quickly build their own products and reduce time-to-market. The OMAP platform ensures that developers can confidently and confidently add voice applications to the growth opportunities of personal handheld devices.
The use of voice technology is increasing, providing a rare opportunity for application developers to add high-value features to handheld devices, mobile devices and wireless personal devices. Today's personal handheld voices are mostly limited to voice dialing, but technologies for more widely developed speech recognition and text-to-speech applications have emerged. Developers looking to add voice capabilities need to be familiar with all aspects of voice technology. These issues include not only processing and memory requirements, but also how specific platform architectures and support can facilitate the development process and reduce time to market.
The use of voice applications to add value can bring huge potential benefits. According to various market research companies, the overall annual growth rate of personal handheld devices is expected to reach 20% in the next two years. By 2004, the total global equipment shipments will reach 700 million. In order to exploit this huge market with value-added voice applications, developers must turn to the underlying technologies that give them high performance, low power consumption and support that will help them quickly introduce new products.
The voice function provides users with a natural way of input and output, which is safer than other forms of I/O, especially when the user is driving. In most applications, speech is an ideal complement to keyboards and displays, not a replacement for them. For example, in a very noisy environment, listening and speaking may not be realistic, so users may have to rely on keyboard input and display reading. Similarly, users often prefer to use the keyboard to enter certain things, such as PIN numbers and passwords, rather than letting them speak out loud.
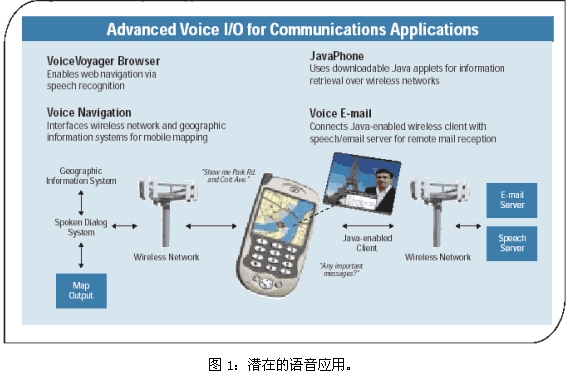
Voice dialing is the most commonly used voice technology in today's personal wireless devices. Voice dialing usually makes calls without the need for hands and ears, which is especially important when driving. Voice dialing includes name dialing, that is, calling by name on the address book, and dialing the number, that is, speaking the phone number. As shown in Figure 1, other potential voice applications include:
1. Voicemail?D?D includes browsing the mailbox, writing emails using voice input, and listening to emails.
2. Information retrieval? D?D stock prices, headline news, flight information, weather forecasts, etc. can all be heard from the Internet by voice. For example, instead of entering a URL and entering a stock name or browsing a predefined list, the user can order: "My stock quote, Texas Instruments ."
3. Personal Information Management? D?D allows users to specify appointments, view calendars, add contact information, and more by voice.
4. Voice browsing? D?D uses the voice program menu, users can surf the Internet, add voice favorites and listen to the reading of web content.
5. Voice navigation? D?D Get the full voice input/output driving system for navigation under the condition of automatic and insufficient eyes.
 |
Voice technology problem
The voice system must meet certain basic usage requirements. Obviously, the voice output must be clear so that the user can understand. ASR must also support natural speech for a given application. What is natural can be described as volatility, from simple names and instructions that are spoken verbatim to continuous statements that speak a lot of vocabulary. In addition, each person's natural voice and pronunciation are different, so the system should be able to flexibly accept the speech of different speakers. The recognition engine must be accurate or the user will not use this technology.
The system requirements for voice are that they require a lot of processing and may contain huge amounts of memory, depending on the supported thesaurus. For server-based applications, the use of wireless bandwidth will increase. These factors also affect other system considerations. The higher the MIPS and transmission requirements of the application, the higher the power consumption of a given system, thus shortening battery life or causing more frequent charging. When an application requires processor external memory, the response time is also likely to increase.
Some application trade-off considerations help to reduce system requirements by abandoning unnecessary functionality of handheld devices. A speaker-based system that recognizes only a small number of words and distracts speech requires much less resources than a speaker-based system that recognizes large lexicons and continuous speech. Support for other languages ​​increases processing requirements and doubles the memory required by the application. Noise and interference immunity are important features, but add complexity and memory requirements.
Obviously, developers want to reduce the performance of basic applications as little as possible while increasing speaker dependencies, continuous speech, lexicon size, and language support. There are certain options to help reduce performance degradation in voice technology, such as Distributed Speech Recognition (DSR). The DSR splits the identification task so that the handheld device can convert the original speech into a spectral characteristic vector while the server performs the recognition process. This approach, as well as similar distributed TTS methods, relies on the standardization of processing methods and transport protocols. Despite the promising nature of these technologies, developers still face limited resources for voice applications in personal handheld devices.
Therefore, choosing the right platform for high-performance applications such as voice is just as important as the ability to design applications. This platform must have powerful processing power while achieving a high level of efficiency, not only in kernel operations, but also in processing memory. There should be enough MIPS to support multimedia, security, and other complementary applications. It is also important to provide programmability to integrate new algorithm capabilities. Finally, this platform must include a software architecture designed to support modular application development to help developers get their products to market quickly.
OMAP technology: an excellent voice platform
TI's OMAP platform provides an excellent solution for developing voice applications in personal handheld devices. The dual-core architecture of the OMAP1510 and OMAP5910 processors integrates the high-efficiency TMS320C55 x? digital signal processor (DSP) and high-performance ARM9RISC microprocessor. Thus, these OMAP processors provide the signal processing capabilities of the arithmetic set required for speech while also providing the general performance required for system layer operation. The OMAP710 processor is a highly integrated single-chip solution with a DSP-based GSM/GPRS baseband for wireless communication processing and a dedicated TI-enhanced ARM925 processor for low-power execution multimedia applications. The OMAP1510, OMAP5910 and OMAP710 processors support low-end ARM-based voice applications. They also have code compatibility, enabling developers to integrate software applications into individual products for different markets. The OMAP1510 and OMAP5910 have DSP processing power to handle more focused voice applications.
Dual core hardware architecture
The dual-core hardware platform of the OMAP1510 and OMAP5910 is designed to maximize system performance and minimize power consumption. When used in personal handheld devices, the combination of DSP and RISC cores provides these processors with unparalleled performance and power advantages. RISC is ideal for handling control code such as user interfaces, OS and advanced applications. On the other hand, DSP is more suitable for real-time signal processing functions required for voice applications.
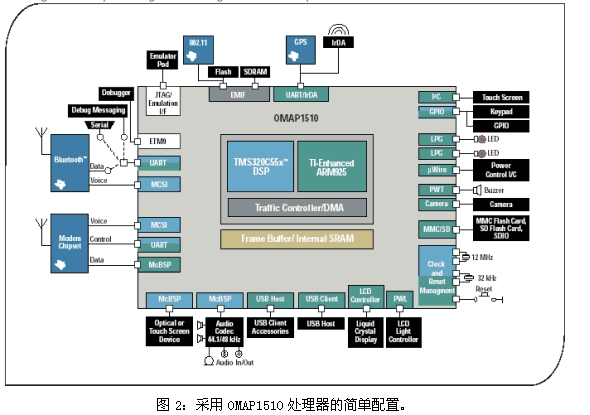
As shown in Figure 2, the OMAP1510 architecture includes an on-chip cache for two processors that reduces the average number of transfers to external memory while eliminating unnecessary external access power. Two core memory management units (MMUs) provide virtual physical memory translation. The low-power mode of operation preserves the ability to use no or little processor.
The OMAP1510 architecture also includes two external memory interfaces and a single memory port. These three memory interfaces are completely independent of each other and can be accessed from either the core or from the DMA unit at the same time. Each processor has its own peripheral interface that supports not only direct connections to peripherals but also DMA connections from the processor DMA unit. On-chip peripherals such as timers, general-purpose I/O, UART, and watchdog timers, as well as color LCD controllers, support the general requirements of the OS.
The OMAP5910 architecture not only provides on-chip system functions but also features such as 192Kbytes RAM, USB1.1 host and client, MMC/SD card interface, multi-channel buffer serial port, real-time clock, GPIO and UART, LCD interface, SPI, uWire and i2s. Peripheral devices inside. Similar to the OMAP1510, the OMAP5910 also includes a built-in interprocessor communication mechanism that provides a transparent interface to the DSP for easier code development.
 |
Designing voice applications for the OMAP platform
In the OMAP Developer Network, TI is working with a number of leading third-party developers who are developing voice technologies such as ASR, TTS, DSR and speaker verification. These companies have their own unique advantages in the market, and they can bring these advantages to OMAP users. At the same time, TI has developed a speech recognition software specifically designed for small vocabulary and small speech recognition that takes full advantage of the dual-core architecture of the OMAP platform. The TI Embedded Speech Recognizer (TIESR) provides the following functions: speaker-independent instructions and speaker-independent continuous digital recognition. Speaker-independent continuous speech recognition. Speaker-related name dialing, command and control. Dynamic grammar and vocabulary features to improve immunity in applications such as voice browsing, noise-free environment, optional speaker adaptation for enhanced performance
Voice application example
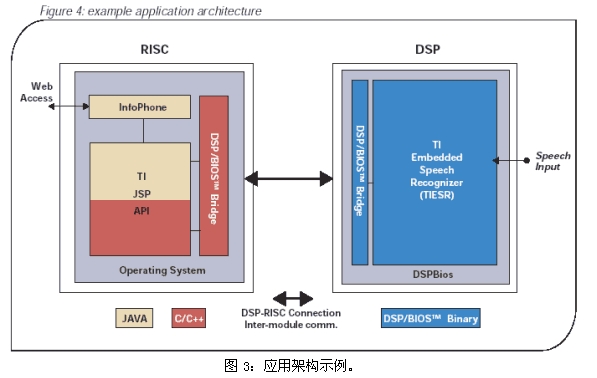
InfoPhone is a classic example of a voice application based on this embedded architecture developed by TI for wireless applications. InfoPhone is a Java application that implements voice capabilities, and it also enables voice retrieval of useful information. TI has developed three prototype voice-based information services for InfoPhone, such as providing stock quotes, flight information and weather forecasts for users. Each service contains a thesaurus of 50 words, because with the dynamic lexicon function, the system can perfectly switch between the thesaurus. The application design keeps keyboard input active during speech, providing flexibility when the environment is interrupted or when the user needs to make private input. Figure 3 illustrates the speech recognition architecture in the InfoPhone example.
 |
This article refers to the address: http://
Window Facing Lcd Display,Window Facing Display,Digital Signage,High Brightness Lcd Display
Shenzhen Risingstar Outdoor High Light LCD Co.Ltd , https://www.risingstarlcd.com