There are three words that appear more and more frequently in these two years: artificial intelligence (AI), machine learning (ML), deep learning (DL), what is their relationship with their brothers? Today, Xiao Bian is very simple and simple, and you can quickly see it with a few pictures. The relationship diagram is also clear from the point of view of the concept:
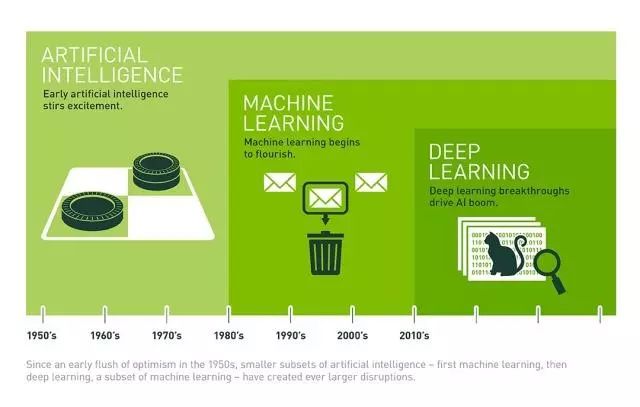
Artificial Intelligence AI: Simulate the human brain, identify which is the apple and which is the orange.

Machine Learning ML: According to the characteristics of buying oranges in the fruit stalls, with more and more oranges and other fruits seen, the ability to identify oranges is becoming stronger and stronger, and bananas will no longer be used as oranges.
Machine learning emphasizes "learning" rather than the program itself, analyzes large amounts of data through complex algorithms, identifies patterns in the data, and makes a prediction - no specific code is required. While the number of samples is increasing, self-correcting and perfecting “learning purposes†can learn from their own mistakes and improve their ability to identify.

Deep Learning DL: There are 3 kinds of apples and 5 kinds of oranges in the supermarket. Through data analysis and comparison, the varieties and data in the supermarket are linked and the ordinary oranges are distinguished by the color, shape, size, maturity, and origin of the fruit. And blood oranges, so choose to buy the orange varieties that users need.
1, a brief history of machine learning
The three ultimate philosophical questions: Who? Where do you come from? Where to go? It makes sense to use it anywhere.
- Nicholas Wobgie Douglas Soder
Although artificial intelligence has not emerged in recent years, it has always appeared as a science fiction element in the public eye. Since AlphaGo's victory over Li Shishi, artificial intelligence has suddenly become an indisputable resource, as if humans have created machines that transcend human wisdom. The core technology of artificial intelligence, machine learning, and deep learning in its sub-fields have become the hearts of people. In the face of this "monster" descending from heaven, there are optimists and pessimists. However, as we trace history, we will find that the outbreak of machine learning technology has its historical inevitability and it is an inevitable product of technological development. Clearing the development of machine learning helps us grasp the overall technical framework of machine learning or artificial intelligence, which helps to understand this technical field from the perspective of "Tao". This section begins with the last two of the three major philosophical questions—from where to where to go—to grasp machine learning as a whole, and then to study in depth from the point of “surgery†to solve the problem of who. (Originally wanted to add a vertical timeline, but unfortunately did not find the method for a long time, if anyone knows, seek to share)
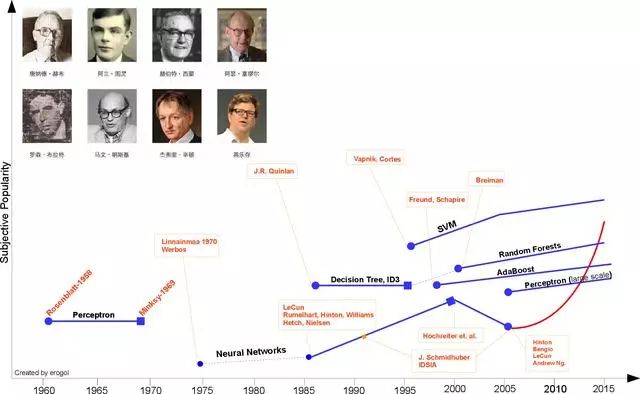
Figure I History of machine learning (Source: Brief History of Machine Learning)
1.1 Birth and lay the foundation period
1949, Hebb, Hebbian Learning theory
Hebby proposed a learning method based on neuropsychology in 1949. This method is called Hebbian learning theory. Generally described as:
It is assumed that the persistence or repetitiveness of reflex activity will lead to continuous changes of cells and increase their stability. When a neuron A can continuously or repeatedly stimulate neuron B, the growth or metabolism of one or both of the neurons will be Variety.
Let us assume that the persistence or repetition of a reverberatory activity (or “traceâ€) tends to induce lasting cellular changes that add to its stability.... When an axon of cell A is near enough to excite a cell B and repeatedly or persistently Part in firing it, some growth process or metabolic change takes place in one or both cells such that A's efficiency, as one of the cells firing B, is increased
From the perspective of artificial neurons or artificial neural networks, the learning theory simply explains the correlation (weight) between nodes in a recurrent neural network (RNN), that is, when two nodes change simultaneously (whether it is Positive or negative, then there is a strong positive correlation between the nodes; if the two are opposite, then there is a negative weight.
1950, Alan Turing, The Turing test
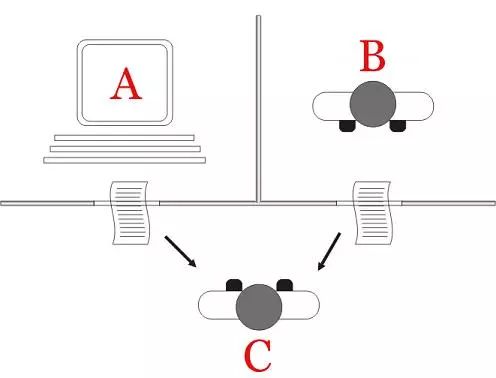
Figure 2 Turing test (Source: Wikipedia)
In 1950, Alan Turing created the Turing test to determine if the computer was smart. The Turing test believes that if a machine can initiate a dialogue with humans (via telex devices) and cannot identify its machine identity, then the machine is called smart. This simplification makes Turing convincingly explain that "thinking machines" are possible.
On June 8, 2014, a chat robot called Eugene Gustmann succeeded in convincing humans that it was a 13-year-old boy and became the first ever computer to pass the Turing test. This is considered a milestone in the development of artificial intelligence.
1952, Arthur Samuel, “Machine Learningâ€

Figure 3 Samuel (Source: Brief History of Machine Learning)
In 1952, IBM scientist Arthur Samuel developed a checkers program. The program can provide better guidance for subsequent actions by observing the current position and learning an implicit model. Samuel found that with the increase in the running time of the game program, it can achieve better and better follow-up guidance. Through this program, Samuel dismissed Providence's proposed machine that cannot transcend humans and write codes and learning patterns like humans. He coined the term "machine learning" and defined it as:
Research areas that can provide computer capabilities without explicit programming
a field of study that gives computer the right without being clearly programmed.
1957, Rosenblatt, Perceptron
Figure 4 Perceptron Linear Classifier (Source: Wikipedia)
In 1957, Rosenblatt proposed a second model based on neuro-perceptual scientific background, very similar to today's machine learning model. This was a very exciting discovery at the time and it was more applicable than Heeb’s idea. Based on this model, Rosenblatt designed the first computer neural network, the perceptron, which simulates how the human brain operates. Rosenblatt defines the perceptron as follows:
Perceptrons are designed to illustrate some of the basic properties of a general intelligence system. They are not tied to individual exceptions or what they don't normally know, and they are not confused by the circumstances of those individual organisms.
The perceptron is designed to demonstrate some of the fundamental properties of intelligent systems in general, without is too deeply enmeshed in the special, and frequently unknown unknown, conditions which hold for specified biological organisms.
Three years later, Verdero first used Delta learning rules (ie least squares) for the sensor training steps, creating a good linear classifier.
In 1967, The nearest neighbor algorithm
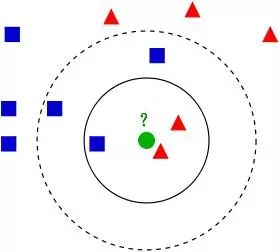
Figure 5 kNN algorithm (Source: Wikipedia)
In 1967, the Nearest Neighbor algorithm emerged, allowing computers to perform simple pattern recognition. The core idea of ​​the kNN algorithm is that if most of the k most adjacent samples in a feature space belong to a certain category, the sample also belongs to this category and has the characteristics of the samples in this category. This is the so-called "minority to majority" principle.
1969, Minsky, XOR problem
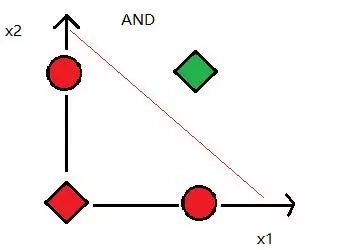
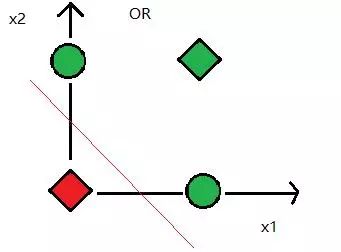
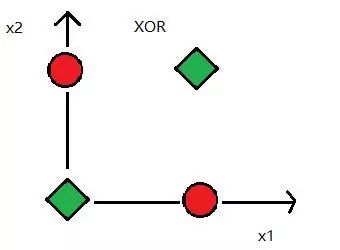
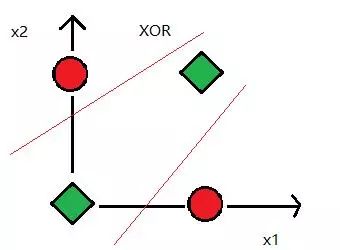
Figure 6 XOR problem, data is linearly inseparable
In 1969, Marvin Minsky proposed the famous XOR problem, pointing out that perceptrons are ineffective in distributing linearly inseparable data. After that, the researchers of the neural network entered the winter and did not recover until 1980.
1.2 Bottleneck period of stagnation
From the mid-1960s to the end of the 1970s, the pace of machine learning was almost at a standstill. Whether it is theoretical research or computer hardware limitations, the development of the entire field of artificial intelligence has encountered a big bottleneck. Although Winston's structural learning system and Hayes Roth's logic-based induction learning system have made great progress during this period, they can only learn a single concept and have not been put into practical use. . However, the neural network learning machine has failed to achieve the desired results due to theoretical defects and it has turned into a low ebb.
1.3 The light of hope relights
1981, Werbos, Multi-Layer Perceptron (MLP)
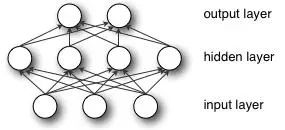
Figure 7 Multilayer Perceptron (or Artificial Neural Network)
Wei Bosi proposed a multilayer perceptron model specifically in the 1981 Neural Network Back Propagation (BP) algorithm. Although the BP algorithm has been proposed in the name of "reverse mode of automatic differentiation" as early as 1970, it has only been effective until now, and until now, BP algorithm is still a neural network architecture. The key factor. With these new ideas, the study of neural networks has accelerated.
In 1985-1986, neural network researchers (Rummelhardt, Hinton, Williams-He, Nielsen) successively proposed the concept of multiparameter linear programming (MLP) trained using the BP algorithm, becoming later deep learning. Cornerstone.
1986, Quinlan, Decision Trees
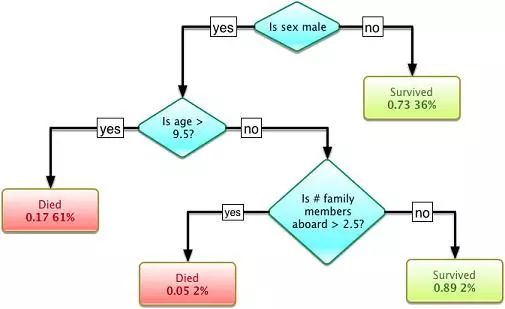
Figure 8 Decision Tree (Source: Wikipedia)
In another pedigree, Quinlan proposed a very famous machine learning algorithm in 1986. We call it the "decision tree", more specifically the ID3 algorithm. This is the breakthrough point of another mainstream machine learning algorithm. In addition, the ID3 algorithm has also been released as a software that can find more real-world cases with simple planning and explicit deductions, which is exactly the opposite of the neural network black box model.
The decision tree is a predictive model. It represents a mapping relationship between object attributes and object values. Each node in the tree represents an object, and each forked path represents a possible attribute value, and each leaf node corresponds to the object represented by the path from the root node to the leaf node. value. A decision tree has only a single output. If you want to have multiple outputs, you can build an independent decision tree to handle different outputs. Decision tree in data mining is a frequently used technology that can be used to analyze data and can also be used for prediction.
After the ID3 algorithm was proposed, the research community has explored many different options or improvements (such as ID4, regression trees, CART algorithms, etc.), and these algorithms are still active in the field of machine learning.
1.4 The Molding Period of Modern Machine Learning
1990, Schapire, Boosting
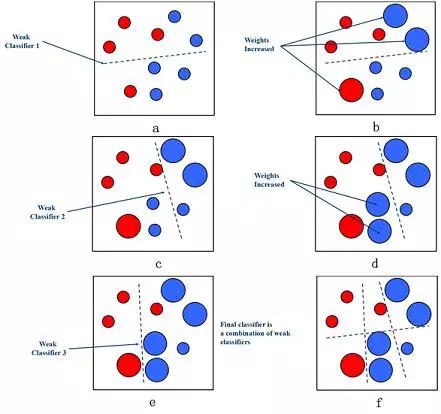
Figure 9 Boosting algorithm (Source: Baidu Encyclopedia)
In 1990, Schapire first constructed a polynomial-level algorithm, which is the original Boosting algorithm. One year later, Freund proposed a more efficient Boosting algorithm. However, these two algorithms have common practical drawbacks, that is, they all require that the weak learning algorithm learn the correct lower limit in advance.
In 1995, Freund and Schapire improved the Boosting algorithm and proposed the AdaBoost (Adaptive Boosting) algorithm. The efficiency of this algorithm is almost the same as the Boosting algorithm proposed by Freund in 1991, but does not require any prior knowledge about the weak learner. Easy to apply to practical problems.
The Boosting method is a method to improve the accuracy of weak classification algorithms by constructing a series of prediction functions and then combining them into a prediction function in a certain way. He is a framework algorithm, which mainly obtains sample subsets through the operation of sample sets, and then uses a weak classification algorithm to train a sample subset to generate a series of base classifiers.
1995, Vapnik and Cortes, Support Vector Machines (SVM)
Figure X. Support vector machine (Source: Wikipedia)
The emergence of support vector machines is another major breakthrough in the field of machine learning. The algorithm has a very strong theoretical position and empirical results. During that period of time, machine learning studies were also divided into NN and SVM. However, after a support vector machine with a kernel function was introduced around 2000. SVM has achieved better results in many tasks previously occupied by the NN. In addition, SVM can also use all the in-depth knowledge about convex optimization, generalized marginal theory and kernel functions relative to NN. Therefore, SVM can greatly promote the improvement of theory and practice from different disciplines.
However, the neural network has been questioned again. The study by Hochreiter et al. (1991) and Hochreiter et al. (2001) showed that the NN neurons will experience gradient loss after saturation when learning with the BP algorithm. Simply put, after a certain number of epochs training, NN will have an overfitting phenomenon, so this period NN is at a disadvantage compared with SVM.
2001, Breiman, Random Forests(RF)
The decision tree model was proposed by Dr. Breman in 2001. It is an algorithm that integrates multiple trees through integrative learning. Its basic unit is a decision tree, and its essence belongs to a major branch of machine learning. Ensemble Learning method. There are two keywords in the name of the random forest, one is "random" and the other is "forest". "Forest" we understand very well, a tree called a tree, then hundreds of trees can be called a forest, this metaphor is still very appropriate, in fact, this is the main idea of ​​random forest - the embodiment of integrated thinking.
In fact, from an intuitive point of view, each decision tree is a classifier (assuming now is the classification problem), then for an input sample, N trees will have N classification results. The random forest integrates all the classification voting results, and specifies the category with the highest number of votes as the final output. This is the simplest Bagging idea.
1.5 The period of the outbreak
2006, Hinton, Deep Learning
The development of machine learning is divided into two parts, Shallow Learning and Deep Learning. The invention of shallow learning The invention of the back propagation algorithm of the artificial neural network in the 1920s made statistically based machine learning algorithms very popular. Even though artificial neural network algorithms at this time are also called multi-layer perceptrons, due to the multi-layer network Difficulties in training are usually shallow models with only one hidden layer.
In 2006, Hinton, a leader in neural network research, proposed the neural network Deep Learning algorithm, which greatly improved the capabilities of neural networks and sent challenges to support vector machines. In 2006, Hinton, a master of machine learning, and his student Salakhutdinov published an article in the leading academic journal Scince, which opened the wave of deep learning in the academic and industrial world.
This article has two main messages: 1) Many hidden layer artificial neural networks have excellent feature learning capabilities, and the learned features have more intrinsic characterization of the data, which facilitates visualization or classification; 2) deep nerves The difficulty of training the network can be effectively overcome by layer-wise pre-training. In this article, layer-by-layer initialization is achieved through unsupervised learning.
In 2015, in commemoration of the 60th anniversary of the concept of artificial intelligence, LeCun, Bengio and Hinton launched a joint review of deep learning.
Deep learning allows computational models with multiple processing layers to learn representations of data with multiple levels of abstraction. These methods have brought significant improvements in many areas, including state-of-the-art speech recognition, visual object recognition, object detection, and many other areas such as drug discovery and genomics. Deep learning can find complex structures in big data. It uses BP algorithm to complete this discovery process. The BP algorithm can instruct the machine how to obtain errors from the previous layer and change the internal parameters of the layer. These internal parameters can be used to calculate the representation. Deep convolutional networks have made breakthroughs in processing images, video, speech, and audio, and recursive networks have shown a shiny side in processing sequence data such as text and speech.
Currently, the most popular methods in statistical learning include deep learning and SVM (support vector machine), which are representative methods of statistical learning. It can be considered that both the neural network and the support vector machine originate from the perceptron.
Neural networks and support vector machines have always been in a "competitive" relationship. The expansion theorem of SVM application kernel function does not need to know the explicit expression of nonlinear mapping; because it is a linear learning machine built in the high-dimensional feature space, compared with the linear model, it not only increases the computational complexity, but also To some extent, avoiding "dimensional disasters." The previous neural network algorithm is relatively easy to train, a large number of empirical parameters need to be set; the training speed is slower, and the effect is not better than other methods when the level is relatively small (less than or equal to 3).
Neural network models seem to be able to achieve more difficult tasks, such as target recognition, speech recognition, natural language processing and so on. However, it should be noted that this absolutely does not mean the end of other machine learning methods. Although the success stories of deep learning have grown rapidly, the training costs for these models are quite high, and adjusting external parameters is also very troublesome. At the same time, the simplicity of SVM makes it still the most widely used machine learning method.
1.6 Inspiration and Future Development
Artificial intelligence machine learning is a young discipline that was born in the middle of the 20th century. It has had a major impact on human production and lifestyle, and it has also triggered fierce philosophical debates. But in general, the development of machine learning is not much different from the development of other common things, and can also be viewed in the light of the development of philosophy.
The development of machine learning has not been easy. It has also undergone a process of spiraling up. Achievements and ups and downs coexist. The achievements of a large number of research scholars have brought unprecedented prosperity to today's artificial intelligence, and it is a process of quantitative change to qualitative change. It is also the common result of internal and external factors.
The development of machine learning explains the importance and necessity of multidisciplinary development. However, this kind of crossover is not simply a matter of knowing a few terms or concepts from each other. It requires real integration:
Statistician Friedman was an early physicist. He was an optimization algorithm master and his programming skills were equally impressive.
Professor Jordan is both a first-class computer scientist and a first-class statistician. His doctoral major is psychology. He can take the responsibility of establishing statistical machine learning.
Professor Sinton is the most famous cognitive psychologist and computer scientist in the world. Although he had achieved great success early on and gained fame in the academic world, he was still active on the line and wrote his own code. Many of the ideas he proposed are simple, feasible and very effective, and they are called great thinkers. It is because of his wise and personal experience that deep learning technology ushered in a revolutionary breakthrough.
...
The success of deep learning does not stem from advances in brain science or cognitive science, but because of the tremendous increase in driving and computing power of big data. It can be said that machine learning is created by academia, industry, entrepreneurs (or the competition industry) and other forces. The academic world is the engine, the industry is the driving force, and the entrepreneurial world is the vitality and future. Academics and industry should have their own responsibilities and division of labor. The responsibility of the academic community lies in the establishment and development of the discipline of machine learning and the training of specialized personnel in the field of machine learning. Large projects and large projects should be driven by the market and implemented and completed by the industry.
As for the future of machine learning, Lu Xiaoling, a teacher of the Academy of Mathematics and Systems Science of the Chinese Academy of Sciences, put forward six questions when he wrote the book “Machine Learning†for the teacher Zhou Zhihua of Nanjing University. I think these problems may affect the future development of machine learning. The basic questions of direction, so I extracted five of them here (there are two questions that belong to the same topic and are merged):
Question one: In the early days of artificial intelligence, the technical connotation of machine learning was almost all symbolic learning. However, since the 1990s, a dark horse has emerged in statistical machine learning, quickly overwhelming and replacing the status of symbol learning. People may ask whether symbol learning has been completely ignored. Can he become a research object for machine learning? Can it continue to stay in the shadow of statistical learning?
The first view: exit the stage of history - no one has this idea.
The second point of view: Statistical learning and symbolic learning are combined. Professor Wang Xi believes that machine learning has reached a turning point. If statistical learning is to enter a more advanced form, it should be combined with knowledge, otherwise it will stay in the status quo. And stop.
The third point of view: There is still a time for symbol learning to come. Professor Chandrasekaran believes that machine learning will not return to "Hexi," but will gradually shift to basic cognitive science as technology advances.
Question 2: Statistical machine learning algorithms are based on the assumption that the sample data are independently and identically distributed, but the phenomenon of the natural world is ever-changing. Where are there so many independent and identical distributions? Is the "independent and identical distribution" condition necessary for machine learning? Is the existence of independence and distribution necessarily an insurmountable obstacle?
Can migration learning bring about a glimmer of problems?
Question 3: There have been some new trends in recent years, such as deep learning. But do they really learn new directions on behalf of the machine?
Some scholars including Mr. Zhou Zhihua believe that the upsurge of deep learning is more than its own contribution. There is not much innovation in theory and technology. Only the revolution of hardware technology allows people to adopt the original algorithm with high complexity. To get more refined results.
Question 4: Since the emergence of machine learning research, we have seen the evolution from symbolic methods to statistical methods. The mathematics used are mainly probability statistics. But today's mathematics is like the sea. Isn't it only statistical methods that are suitable for machine learning?
At present, popular learning has been “somewhat meaningfulâ€, but the degree of involvement in mathematical theory is far from enough. It needs to involve more mathematicians and open up new models, theories and methods.
Question 5: Does the emergence of the era of big data have an essential impact on machine learning?
The era of big data has brought unprecedented opportunities for machine learning, but are the same statistics and sampling methods fundamentally different from before? Is it from quantitative change to qualitative change? Is there a qualitative change in mathematical statistics? What kind of machine learning methods are being called for in the era of big data? Which methods are driven by big data research?
2, the basic concept of machine learning
Authoritative definition:
Arthur samuel: A field of study that gives computer learning ability without programming directly to problems.
Tom Mitchell: For a certain class of tasks T and performance metrics P, if a computer program self-performs with the experience E in terms of performance measured on P, then the computer program is said to learn from experience E.
In fact, with the deepening of learning, it will gradually find that machine learning is increasingly difficult to define, because the fields involved are very wide and the application is also very wide. Now it is basically a standard for computer-related majors, but in the actual operation process, It will slowly be discovered that in fact, machine learning is also a very simple thing. Most of our most things are actually two things. One is the classification and the other is the return. For example, the prediction of house prices and the forecast of stock prices are regression problems. Emotional discrimination and the issue of credit cards are classified. The reality is generally given us a bunch of data. We extract the features that best express the data based on our professional knowledge and some experience. Then we use an algorithm to model, and when we have unknown data, we can predict that this belongs to Which category or what value is predicted to make the next decision. For example, the face recognition system is used as a verification system. It may be a rights management. If it is a person in the system, it has the authority or else it does not have the right. The data first given to us is a pile of photos of people's faces. The thing to do is to preprocess the data, then extract facial features, and finally choose an algorithm such as SVM or RF, etc. The final choice of algorithm is designed to the evaluation criteria. This will be followed specifically so that we build a person. Face recognition model, when the system inputs a face, we can know whether he is in the system. The whole process of machine learning is just a few steps. The last step is parameter optimization, including the now full-fledged machine learning.
When we judge whether we want to learn the machine, we can see if it is the following scenario
Humans cannot be programmed manually;
What is the solution that humans cannot define this problem well?
Humans cannot make systems that require extremely rapid decision-making;
Large-scale personalized service system;

3, machine learning classification
3.1 Supervised Learning
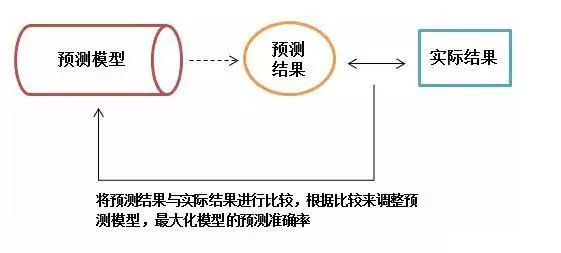
Under supervised learning, each set of training data has an identification value or result value. For example, the customer loss corresponds to 1 and no loss corresponds to 0. When establishing a predictive model, supervised learning establishes a learning process, compares the predicted results with the actual results of the training data, and continuously adjusts the predictive model until the predictive results of the model reach an expected accuracy.
Classification
K nearest neighbors K-Nearest Neighbor (KNN)
Naive Bayes Naive Bayes
Decision Tree: Decision Tree C4.5: Classification and Regression Tree (CART)
Support Vector Machine Support Vector Machine (SVM)
Return to Regression
Linear regression
Locally weighted regression
Logistic regression logistic Regression
Stepwise regression
Multivariate adaptive regression spline multivariate adaptive regression splines
Locally estimated scatter plot smoothing (LOESS)
Ridge Regression Ridge Regression
Least Absolute Shrinkage and Selection Operator (LASSO )
Elastic Net Elastic Net
Polynomial Regression
Sort Rank
Single document classification Pointwise: McRank
Pairwise: Ranking SVM, RankNet, Frank, RankBoost
Listwise method: AdaRank, SoftRank, LambdaMART
Match learning
Artificial Neural Network: Perception Neural Network, Perceptual Neural Network, Back Propagation, Hopfield Network, Self-Organizing Map (SOM), Learning Vector Quantization (LVQ)
3.2 Semi-supervised learning
In the semi-supervised learning mode, part of the training data is identified and some of the training data are not identified. This model first needs to learn the internal structure of the data in order to reasonably organize the data for prediction. Algorithms include some extensions to commonly used supervised learning algorithms. These algorithms first try to model the unidentified data, and then predict the identified data. Such as deep learning:
Deep Learning Deep Learning
Deep learning is developed through the extension of artificial neural networks in supervised learning.
Restricted Boltzmann Machine ( RBM )
Deep Belief Networks (DBN)
Convolutional Network Convolutional Network
Stacked self-encoding Stacked Auto-encoders
3.3 Unsupervised Learning Unsupervised Learning
In unsupervised learning, data is not specifically identified. The learning model is to infer some of the internal structure of the data.
Clustering Cluster
K-means k-means
Maximum Expectation Algorithm Expectation Maximization (EM)
Dimensionality Reduction: Principal Component Analysis (PCA), Partial Least Squares Regression (PLS), Sammon Mapping, Multidimensional Scaling (MDS), Projection Pursuit, RD
Association Rule
Apriori
Eclat
3.4 Reinforcement Learning
In the previous discussion, we always gave a sample x, and then gave or did not give the identity or result value (given supervised learning, not supervised learning). Afterwards, the sample is fitted, classified, clustered or reduced in dimension. However, it is difficult to have such a regular sample for many sequence decision or control problems. For example, the control problem of the quadruped robot did not know that it should be allowed to move the leg at first. During the movement process, it did not know how to let the robot automatically find a suitable direction of advancement.
Reinforcement learning is to solve the problem: an autonomous agent that can sense the environment, how to choose the best action to achieve its goal through learning. This very common problem applies to the learning and control of mobile robots, learning the best operating procedures in the factory and learning chess chess and so on. When an agent makes each action in its environment, the teacher provides reward or punishment information to indicate whether the resulting status is correct or not. For example, when training an agent to play a chess game, the teacher can give a positive return when the game is victorious, and give a negative return when the game fails, and a zero return at other times. The task of the agent is to learn from this indirect, delayed reward so that subsequent actions have the greatest cumulative effect.
Q-Learning
Temporal difference learning
3.5 Others
Integrated algorithm
The integration algorithm uses a relatively weak learning model to train the same sample independently and then integrates the results for overall prediction.
Boosting
Bootstrapped Aggregation ( Bagging )
AdaBoost
Stack Generalization
Gradient Boosting Machine (GBM)
Random Forest Random Forest
The multimedia wiring harness apply to Audio,Video,Radio, LVDs,Flat RCA,USB.
Yacenter has experienced QC to check the products in each process, from developing samples to bulk, to make sure the best quality of goods. Timely communication with customers is so important during our cooperation.
If you can't find the exact product you need in the pictures,please don't go away.Just contact me freely or send your sample and drawing to us.We will reply you as soon as possible.
Electric Fan Wiring Kit,Socket Fan Wiring Harness,Custom Pc Wiring Harness,Multimedia Wiring Harness
Dongguan YAC Electric Co,. LTD. , https://www.yacentercns.com