First of all, what is tensor? That is, high-dimensional vectors, for example, the matrix is ​​two-dimensional, and tensor is an n-dimensional vector in a broader sense (with type+shape)
TensorFlow execution process is a definition diagram, in which sub-nodes are defined, and only the nodes on which the required nodes depend are calculated. It is an efficient and adaptable to large-scale data calculation, which is convenient for distributed design. For complex neural network calculations, It is taken apart from other cores and calculated simultaneously.
Theano - torch - caffe (especially image processing) - deeplearning5j - H20 - MXNet, TensorFlow
Operating environmentDownload docker
Open docker quickstart terminal
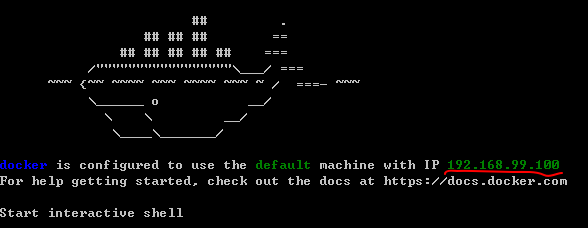
The red dot shows the docker virtual machine IP address (that is, the localhost after)
Docker tensorflow/tensorflow //Automatically find the TensorFlow container and download it
Docker images //Browse the current container
Docker run -p 8888:8888 tensorflow/tensorflow //Run on port 8888
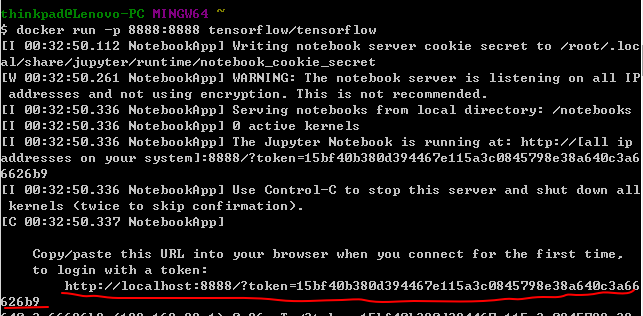
A token will appear, copy the link and replace localhost, either open a writer for TensorFlow, jupyter
Gross prototype #python import import tensorflow as tf# define variable (node) x = tf.Variable(3, name="x")y = tf.Variable(4, name="y")f = x*x*y + y + 2#definition sessionsess = tf.Session()# Assign values ​​to already defined nodes sess.run(x.initializer)sess.run(y.initializer)#Run sessionresult = sess.run(f)print(result) #42#Free space sess.close
There is also a more concise definition and running the session method.
# a better waywith tf.Session() as sess: x.initializer.run() y.initializer.run() #å³evaluate, solve the value of f result = f.eval()
The two lines of initialization can also be written
Init = tf.global_variables_initializer()
Init.run()
The session can be changed to sess=tf.InteractiveSession() to make it easier to run.
Init = tf.global_variables_initializer()sess = tf.InteractiveSession()init.run()result = f.eval()print(result)
Thus TensorFlow's code is divided into two parts, the definition part and the execution part.
TensorFlow is a graph operation with an automatic default default map and your own defined map
#系统 default default diagram>>> x1 = tf.Variable(1)>>> x1.graph is tf.get_default_graph()True#Customized diagram>>> graph = tf.Graph()>>> with Graph.as_default():x2 = tf.Variable(2)>>> x2.graph is graphTrue>>> x2.graph is tf.get_default_graph()The life cycle of the False node
The second method can find the public part and avoid x being calculated twice.
The values ​​of all nodes are cleared after the end of the run. If they are not saved separately, you need to run again.
w = tf.constant(3)x = w + 2y = x + 5z = x * 3with tf.Session() as sess: print(y.eval()) # 10 print(z.eval()) # 15with tf .Session() as sess: y_val, z_val = sess.run([y, z]) print(y_val) # 10 print(z_val) # 15Linear Regression with TensorFlow
(Application on linear regression)
y = wx+b = wx' //where x' is a vector with one dimension all than 1 compared to x
Citing California housing data here
The vector on TensorFlow is a column vector, which requires reshape(-1,1) to be transposed into a column vector.
Solve using the normal equation methodImport numpy as npfrom sklearn.datasets import fetch_california_housinghousing = fetch_california_housing()#Get the data dimension, the row and column length of the matrix m, n = housing.data.shape#np.c_ is the meaning of the connection, plus a dimension of all 1 housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]#The amount of data is not large, you can load it directly with the constant node, but then the massive data cannot be used (the data will be imported by minbatch) X = tf.constant(housing_data_plus_bias, dtype=tf.float32, name="X")# Transposed into a column vector y = tf.constant(housing.target.reshape(-1, 1), dtype=tf.float32, Name="y")XT = tf.transpose(X)# Use the normal equation method to solve the theta. The previous linear model mentioned theta = tf.matmul(tf.matmul(tf.matrix_inverse(tf.matmul(XT, X)), XT), y)# find the weight with tf.Session() as sess: theta_value = theta.eval()
If it is the original method, it may be more direct. However, because the underlying libraries are different, the values ​​they calculate are not exactly the same.
#使用numpyX = housing_data_plus_biasy = housing.target.reshape(-1, 1)theta_numpy = np.linalg.inv(XTdot(X)).dot(XT).dot(y)#Use sklearnfrom sklearn.linear_model import LinearRegressionlin_reg = LinearRegression ()lin_reg.fit(housing.data, housing.target.reshape(-1, 1))
I can't help but wonder why TensorFlow feels complicated. In fact, this is because the size of the data here is small, and the large-scale calculations, the effect of TensorFlow's automatic optimization is very powerful.
Solve using the gradient descent method# Use gradient when you need to scale from sklearn.preprocessing import StandardScalerscaler = StandardScaler()scaled_housing_data = scaler.fit_transform(housing.data)scaled_housing_data_plus_bias = np.c_[np.ones((m, 1)), scaled_housing_data]# iteration 1000 times N_epochs = 1000learning_rate = 0.01# Since using gradient, the value of writing x needs to be scaled X = tf.constant(scaled_housing_data_plus_bias, dtype=tf.float32, name="X")y = tf.constant(housing.target.reshape( -1, 1), dtype=tf.float32, name="y")#Using gradient requires an initial value of theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0), Name="theta")# The current predicted y, x is m*(n+1), theta is (n+1)*1, just the dimension of y y_pred = tf.matmul(X, theta, name=" Predictions")#Overall error error = y_pred - y#TensorFlow solves the mean value powerfully, you can specify the dimension, or you can find the whole mse = tf.reduce_mean(tf.square(error), name="mse") # Temporarily write the training process yourself, you can actually use the more powerful automatic function of TensorFlow. Solution autodiff method gradients = 2/m * tf.matmul(tf.transpose(X), error)training_op = tf.assign(theta, theta - learning_rate * gradients)# Initialize and start solving init = tf.global_variables_initializer()with tf .Session() as sess: sess.run(init) for epoch in range(n_epochs): # Print the current average error every 100 times if epoch % 100 == 0: print("Epoch", epoch, "MSE = ", mse.eval()) sess.run(training_op) best_theta = theta.eval()
The autodiff in the above code is as follows, you can automatically find the gradient
Gradients = tf.gradients(mse, [theta])[0]
Use Optimizer
The entire gradient descent and iterative methods described above are encapsulated in the following method
Optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
Training_op = optimizer.minimize(mse)
There are still many such optimizers.
For example, the optimizer with impulse = tf.train.MomentumOptimizer(learning_rate=learning_rate,momentum=0.9)
Feeding data to training algorithm
When the amount of data reaches several G, tens of G, it is obviously unrealistic to use Constant to directly import data, so we use placeholder to make a placeholder.
(General lines are none, that is, the amount of data is arbitrary)
Really run, feed data when run. New data can be used continuously.
>>> A = tf.placeholder(tf.float32, shape=(None, 3))>>> B = A + 5>>> with tf.Session() as sess:... B_val_1 = B.eval( Feed_dict={A: [[1, 2, 3]]})... B_val_2 = B.eval(feed_dict={A: [[4, 5, 6], [7, 8, 9]]}). ..>>> print(B_val_1)[[ 6.7.8.]]>>> print(B_val_2)[[ 9.10.11.][ 12.13.14.]]
In this way, it is possible to randomly extract a specified amount of data in batches by defining min_batch, and even a few T data can be extracted.
Batch_size = 100n_batches = int(np.ceil(m / batch_size))# There is a random extracted data def fetch_batch(epoch, batch_index, batch_size): #definition a random seed np.random.seed(epoch * n_batches + batch_index) # not shown in the book indices = np.random.randint(m, size=batch_size) # not shown X_batch = scaled_housing_data_plus_bias[indices] # not shown y_batch = housing.target.reshape(-1, 1)[indices] # not Shown return X_batch, y_batch# starts running with tf.Session() as sess: sess.run(init)# Extract new data each time for training for epoch in range(n_epochs): for batch_index in range(n_batches): X_batch , y_batch = fetch_batch(epoch, batch_index, batch_size) sess.run(training_op, feed_dict={X: X_batch, y: y_batch})#final result best_theta = theta.eval()
Saving and Restoring modelsSometimes, a model that runs for a few days may not be able to continue running for a while, so it is necessary to temporarily maintain the trained part of the model onto the hard disk.
Init = tf.global_variables_initializer()saver = tf.train.Saver()#Save the model with tf.Session() as sess: sess.run(init) for epoch in range(n_epochs): if epoch % 100 == 0: #print("Epoch", epoch, "MSE =", mse.eval()) save_path = saver.save(sess, "/tmp/my_model.ckpt") sess.run(training_op) best_theta = theta.eval() Save_path = saver.save(sess, "/tmp/my_model_final.ckpt")#Recover the model with tf.Session() as sess: saver.restore(sess, "/tmp/my_model_final.ckpt") best_theta_restored = theta.eval( ) About TensorBoard
As we all know, neural networks and machine learning are mostly black box models, which makes people a little embarrassed. TensorBoard's function is to whiten the black box slightly~
Enable tensorboard
Enter docker ps to view the current container id

Entering the container
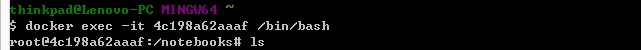
Use the tensorboard --log-dir=tf_logs command to open the already saved tf_logs file. The generated code is as follows:
From datetime import datetimenow = datetime.utcnow().strftime("%Y%m%d%H%M%S")root_logdir = "tf_logs"logdir = "{}/run-{}/".format(root_logdir, Now)...mse_summary = tf.summary.scalar('MSE', mse)file_writer = tf.summary.FileWriter(logdir, tf.get_default_graph())...if batch_index % 10 == 0: summary_str = mse_summary. Eval(feed_dict={X: X_batch, y: y_batch}) step = epoch * n_batches + batch_index file_writer.add_summary(summary_str, step)
Dual Power Supply,Switching Power Supply,Dual Mining Power Supply,Dual-Circuit Power Supply
Easy Electronic Technology Co.,Ltd , https://www.pcelectronicgroup.com