This article guides reading
This article describes how to use mailboxes, message queues, and spin locks. The semaphore can only be used for synchronization between tasks and cannot pass more information. For this reason, AWorks provides mailbox and message queue services. Their main difference is that the length of the supported messages is different. In the mailbox, the length of each message is Fixed to 4 bytes, and in the message queue, the length of the message can be customized. This article is "Programming for AWorks Frameworks and Interfaces (on)" Part 3 - Software - Chapter 10 - Sections 3 - 5: Mailboxes, Message Queues, and Spinlocks.10.3 E-mail
The three semaphores used for synchronization between tasks are described earlier. They correspond to the key of the resource. Tasks that obtain the key can access related resources. The task determines the time that can be run. However, the semaphore cannot provide more information content. For example, when a button is pressed, a semaphore is released. When the task acquires the semaphore, only the button is pressed but the button is not known. For example, which button is pressed?
When you need more information to pass between tasks, you can use the mailbox services provided by AWorks. Mailbox service is a typical inter-task communication method in the real-time kernel, characterized by relatively low overhead and high efficiency. A mailbox can store multiple emails. Each email in a mailbox can only hold a fixed 4 bytes of content (for 32-bit processing systems, the size of the pointer is 4 bytes, so one email can exactly accommodate one pointer). The task of sending mail (or interrupt service program) is responsible for storing the mail in the mail box, and the task of receiving the mail is responsible for extracting the mail from the mail box. The schematic diagram is shown in Figure 10.4.
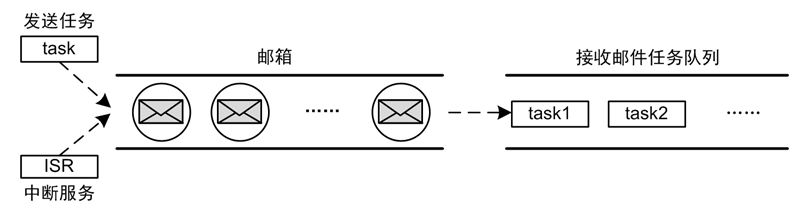
Figure 10.4 Mailbox Operation Diagram
When there are multiple emails in the mailbox, the task of receiving emails is transmitted in accordance with the principle of first-in, first-out (FIFO). The size of the mail is fixed at 4 bytes. When the content of the message to be transmitted is greater than 4 bytes, the address of the message can be used as the mail content. When the task receives the mail, the corresponding message can be found through the address. This approach makes it very efficient to use mailboxes for messaging.
AWorks provides several macros for using the mailbox. The prototype of the macro is shown in Table 10.7.
Table 10.7 Mailbox-Related Macros (aw_mailbox.h) 
1. Define the mailbox entity
AW_MAILBOX_DECL() and
The AW_MAILBOX_DECL_STATIC() macro is used to define a mailbox entity that allocates the necessary memory space for the mailbox, including the space for storing the message. Their prototype is:

Among them, the parameter mailbox is the identification name of the mailbox entity. Mail_num indicates the capacity of the mailbox, which is the maximum number of mails stored in the mailbox. Since the size of each mail is 4 bytes, the total memory size for storing the mail is: mail_num×4.
The difference between the two macros is:
AW_MAILBOX_DECL_STATIC() uses the keyword static when defining the memory required for the mailbox. In this way, the scope of the mailbox entity can be confined within the module (inside the file), thereby avoiding conflicting mailbox naming between modules. You can also use this macro to define a mailbox entity within a function.
If you use AW_MAILBOX_DECL() to define a mailbox entity named mailbox_test, the maximum number of emails is 10. For an example program, see Listing 10.49.
Listing 10.49 Sample program for defining a mailbox entity

When you use AW_MAILBOX_DECL() to define a mailbox entity, you can embed the entity of the mailbox in another data structure with the sample application program listing 10.50.
Listing 10.50 Embedding a Mailbox Entity in a Structure

You can also use AW_MAILBOX_DECL_STATIC() to define a mailbox entity named mailbox_test. For an example program, see Listing 10.51.
Listing 10.51 Example Program for Defining a Mailbox Entity (Static)
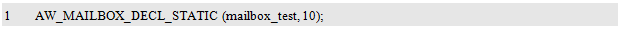
2. Initialize the mailbox
After defining the mailbox entity, it must be initialized using AW_MAILBOX_INIT() before it can be used. Its prototype is:

Where mailbox is the mailbox defined by AW_MAILBOX_DECL() or AW_MAILBOX_DECL_STATIC(). Mail_num indicates the number of mails that can be stored in the mailbox, and its value must be the same as mail_num when defining the mail entity. Options is the mailbox option, which determines the queuing mode of tasks that are blocked in this mailbox (wait message). They can be queued according to task priority or first-in first-out order. Their corresponding macros are detailed in Table 10.8.
Table 10.8 Mailbox Initialization Options Macro (aw_mailbox.h)

Note that the three types of semaphores are described earlier. In initialization, the queuing mode of tasks blocked by semaphores can also be specified by options. The queuing methods are divided into two methods: priority and first-in first-out. Their corresponding macro names are AW_SEM_Q_PRIORITY and AW_SEM_Q_FIFO. Unlike the naming of mailbox options, they cannot be mixed.
Usually, the queue mode is selected to be queued according to the priority. The sample program for initializing the mailbox is detailed in the program listing 10.52.
Listing 10.52 Example procedure for initializing a mailbox

AW_MAILBOX_INIT() is used to initialize a mailbox entity. After initialization, it will return the ID of the cancellation mailbox, whose type is aw_mailbox_id_t. Define a variable of this type to save the returned ID as follows:

The specific definition of aw_mailbox_id_t need not be concerned by the user. The ID can be used as a parameter of other mailbox related interface functions introduced later to specify the mailbox to be operated. In particular, if the value of the return ID is NULL, the initialization failed. In general, if there is no special requirement, the ID will not be used and the ID may not be saved.
3. Get a message from the mailbox
The macro prototype for getting a message from the mailbox is:

Where mailbox is the mailbox defined by AW_MAILBOX_DECL() or AW_MAILBOX_DECL_STATIC(). P_data points to the buffer used to save the message. After the message is successfully retrieved, it will be stored in the buffer pointed to by p_data. Since the size of the message is fixed at 4 bytes (32 bits), the size of the buffer must also be 4 bytes. For example, it can be a pointer to 32-bit data. Timeout specifies the timeout period. The return value of this macro is the standard error number of type aw_err_t. Note that since the interrupt service routine cannot be blocked, this function is prohibited from calling during interrupts.
If the mailbox is not empty and contains a valid message, this operation will successfully obtain a message. At the same time, the message will be deleted from the mailbox and the number of valid messages minus one. At this point, the return value of AW_MAILBOX_RECV() is: AW_OK.
If the mailbox is empty and there is no valid message, the message cannot be obtained immediately. The specific behavior will be determined by the value of the timeout timeout.
(1) If the value of timeout is
AW_MAILBOX_WAIT_FOREVER. The task will block this, waiting until there is a message available in the mailbox, that is, other tasks or interrupts sent the message. The sample program is detailed in Listing 10.53.
Listing 10.53 Sample Program for Permanent Blocking of Waiting Mailboxes
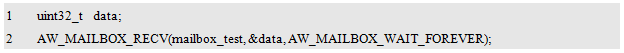
(2) If the value of timeout is
AW_MAILBOX_NO_WAIT. Then the task will not be blocked and return immediately, but the message will not be successfully obtained. At this time, the return value of AW_MAILBOX_RECV() is:
-AW_EAGAIN (indicates that the current resource is invalid and needs to be retried). The sample program is detailed in Listing 10.54.
Listing 10.54 Example program that does not block waiting mailboxes
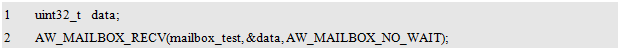
(3) If the value of tiemout is a positive integer, it indicates the longest wait time (in units of system ticks). The task will be blocked. In the timeout specified time, if a message is successfully obtained, AW_MAILBOX_RECV() The return value is: AW_OK; if no message is obtained within the time specified by timeout, the return value is -AW_ETIME (indicating timeout). The sample program is detailed in Listing 10.55.
Listing 10.55 Sample Program for Waiting Mailbox Timeout with 500ms

4. Send a message to the mailbox
The macro prototype for sending messages to the mailbox is:

Where mailbox is the mailbox defined by AW_MAILBOX_DECL() or AW_MAILBOX_DECL_STATIC(). Data is the 32-bit data sent. Timeout specifies the timeout period. Priority specifies the priority of the message. The return value of this macro is the standard error number of type aw_err_t.
If the mailbox is not full, you can continue to store the message. The message is sent successfully and the number of valid messages in the mailbox is increased by 1. At this point, the return value of AW_MAILBOX_SEND() is: AW_OK.
If the mailbox is full and messages cannot be stored for the time being, the message cannot be sent immediately. The specific behavior will be determined by the value of the timeout timeout.
(1) If the value of timeout is
AW_MAILBOX_WAIT_FOREVER. The task will stop here and wait until the message is successfully placed in the mailbox. That is, other tasks get a message from the mailbox, leaving free space in the mailbox. The sample program is detailed in Listing 10.56.
Listing 10.56 Sample Program for Permanent Blocking of Waiting Mailboxes

Note that the priority parameter specifies the priority of the message. There are two possible values: AW_MAILBOX_PRI_NORMAL and AW_MAILBOX_PRI_URGENT, which represent the normal priority and the emergency priority, respectively. Normally, ordinary priorities are used. In this case, new messages are queued to the mailbox in sequence according to the first-in, first-out principle. This message will be fetched from other messages in the current mailbox. If an emergency priority is used, a new message is queued at the head of the mailbox and the message will be fetched before other messages in the current mailbox, ie, will be fetched the next time a message is obtained from the mailbox.
(2) If the value of timeout is
AW_MAILBOX_NO_WAIT. The task will not be blocked, and immediately return, but will not successfully send a message. At this time, the return value of AW_MAILBOX_SEND() is: -AW_EAGAIN (indicates that the current resource is invalid and needs to be retried). The sample program is detailed in Listing 10.57.
Listing 10.57 Sample Programs That Do Not Block Waiting Mailboxes

(3) If the value of tiemout is a positive integer, it means the longest waiting time (in units of system ticks). The task will be blocked. In the time specified by timeout, if the message is successfully sent, the AW_MAILBOX_SEND() returns. The value is: AW_OK; if the message is not successfully sent within the time specified by timeout, the return value is -AW_ETIME (indicating timeout). The sample program is detailed in Listing 10.58.
Listing 10.58 Sample Program for Waiting for a Mailbox with a Timeout of 500ms

Note that in the interrupt service routine (such as a key callback function), you can use this interface to send messages to the mailbox. This is an important communication method between interrupts and tasks: sending messages in an interrupt and receiving messages in a task. And deal with, thereby reducing the interrupt service routine time. However, since the interrupt cannot be blocked, the timeout flag can only be AW_MAILBOX_NO_WAIT when the message is sent in the interrupt. In this application, in order to avoid message loss, the mailbox should be avoided as much as possible. The mailbox can be processed as soon as possible by increasing the capacity of the mailbox and increasing the priority of processing the message.
5. Termination of the mailbox
When a mailbox is no longer in use, the mailbox can be terminated. The macro prototype is:

Where mailbox is the mailbox defined by AW_MAILBOX_DECL() or AW_MAILBOX_DECL_STATIC(). After the mailbox is terminated, if there is still a task waiting for the mailbox in the current system, any task waiting for the mailbox will be unblocked, and -AW_ENXIO (indicating that the resource no longer exists) will be returned. For an example, see Listing 10.59.
Listing 10.59 Example procedure for terminating a mailbox

When talking about counting semaphores, a single button is used to control the LED flip. Since only one button is used, when sending a button message, only the counting semaphore is needed to count the button events without sending more messages. If it is necessary to use a plurality of buttons to control the LEDs, the key code information must be carried when the key message is sent, so that different keys can be processed differently.
For example, to implement a simple application, the current key code is displayed via the LED:
When KEY_0 is pressed, LED0 goes out, LED1 goes out, and "00" is displayed.
When KEY_1 is pressed, LED0 goes out, LED1 lights up, and "01" is displayed;
When KEY_2 is pressed, LED0 is on, LED1 is off, and “02†is displayed;
When KEY_3 is pressed, LED0 is on, LED1 is on, and “03†is displayed.
Obviously, in order to distinguish between different keys, when a key message is sent, it is necessary to carry coded information of the key. Since the key code is data of type int, in a 32-bit system, it is exactly 32 bits. Therefore, a key message can be managed by using a mailbox. The sample program is detailed in Listing 10.60.
Listing 10.60 Mailbox Usage Example Program

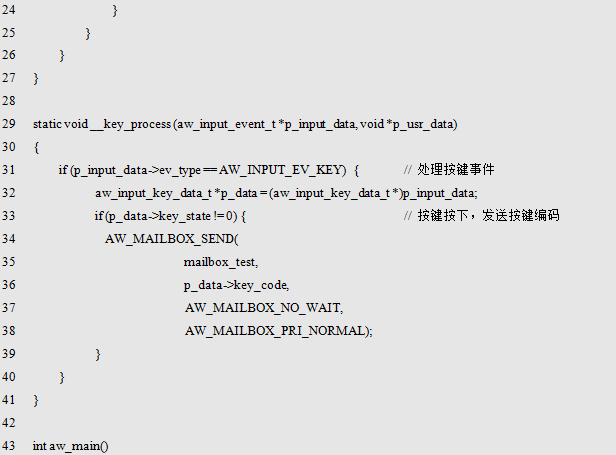

Sending a message in a key event callback function, since only the key press event needs to be processed, the message (key code) is only sent to the mailbox when the key is pressed (key_state is not 0). Receives a message in the task_led task. When a message is successfully obtained, the LED is controlled according to the content of the message (key code).
In fact, the keystroke processing program here is only used to control the LED light. The time-consuming time is very short, and it is often shorter than the time to send a message. The use of the mailbox here does not optimize the program, just as an example of using a mailbox. The actual application of key processing is usually much more complicated, it is recommended to use this common mode, that is, in the key event callback function, just send the key code to the mailbox, the actual processing is completed in the task. This can avoid long-term use of interrupted, affecting the real-time system, so that other emergency services can not be handled, at the same time, the mailbox has a buffering effect, when the button is too late to handle, it can be temporarily stored in the mailbox, and then after the idle time Timely processing, to a great extent avoid the possibility of "lose key", just like the PC, sometimes the system is stuck, the screen is stuck, but the key input information will still be displayed, generally will not be lost.
In the above example program, because the size of the key code is 4 bytes, the mail can just accommodate, therefore, the key code can be directly encoded as the message content and sent to the mailbox (copy one copy and store it in the mail box). If the message to be sent is larger than 4 bytes, obviously it cannot be directly sent. At this time, the address of the transmission content can be sent as the content of the e-mail to the e-mail box. After the e-mail is received by the receiver, the e-mail content is taken as the address and taken out of it. The actual message content. The sample program is detailed in Listing 10.61.
Listing 10.61 Mailbox Usage Example Program - Message Content Greater Than 4 Bytes




In the program, two tasks are defined: task0 and task1. Task0 is responsible for sending messages. The value of count is incremented by 1s every 1s. If count is odd, information in the __g_str1 character array is sent; if count is even, the information in the __g_str2 character array is sent. The two character arrays __g_str1 and __g_str2 store strings:
"The count is an odd number!" and
"The count is an even number!". Obviously, the length of the string exceeds 4 bytes, so the size of both arrays also exceeds 4 bytes. When tsak1 sends the message, the address of the string array is sent as a message to the mailbox. Task1 is used to receive messages. When the message is received, it is used as the address of the character array. Use aw_kprintf() to print the received character information. This completes the delivery of the message.
Because the mailbox only transmits the address of two character arrays, in order to ensure that the receiving task correctly extracts the actual message in the address, it must ensure that the data in the address is still valid when the receiving task receives the mail. Therefore, in the sample program, two arrays are defined as global variables and their memory is always valid. Even after the message processing is completed, the memory space of the array is still valid.
In some applications, when the message is processed, the message will have no practical meaning, and the corresponding data in its address may be discarded to release the relevant memory. At this point, you can use dynamic memory to manage messages: The sender dynamically obtains a piece of memory space, fills the relevant content, the first address of this memory space is sent to the mailbox, the recipient gets the address from the mailbox, and then from the address The actual message content is extracted for processing, and after the processing is completed, the memory is released.
For example, on the basis of Listing 10.60, the function is simply modified: When the key is pressed, the LED shows the current key code, and when the key is released, all the LEDs are extinguished. Obviously, due to the need to deal with key presses and release differently, this requires that after the key event is generated, in addition to the need to send the key code information, the state of the key (press or release) is also sent. At this point, the message needs to contain the key code and key state, a total of 8 bytes. The sample program is detailed in Listing 10.62.
Listing 10.62 Mailbox Usage Example Program - Message Memory Dynamic Allocation




In the program, aw_mem_alloc() and
Aw_mem_free() performs message memory application and release.
Aw_mem_alloc() and aw_mem_free() are the same as standard C's malloc() and free() functions for dynamic memory management. They are declared in the aw_mem.h file.
The function prototype of aw_mem_alloc() is:

It is used to allocate size bytes of memory space and return pointers of type void*, which point to the first address of the allocated space. If memory allocation fails, the return value is NULL.
The function prototype of aw_mem_free() is:

It is used to free space allocated by aw_mem_alloc(). The ptr parameter is the first address of the memory space and its value must be returned by the aw_mem_alloc() function.
10.4 Message Queue
In front of the introduction of the mailbox service, the size of the mailbox fixed message is 4 bytes, when the need to transport more than 4 bytes of content, often need to use the form of a pointer, that is, use the mailbox to pass the first address of the actual message, passed between the tasks Address sharing information. The use of address sharing information is very efficient. However, in this case, special care must be taken to apply for and release memory. After the message in an address is used, it is necessary to release the relevant memory space. For beginners, it is relatively cumbersome to use and error-prone.
To this end, AWorks provides another messaging mechanism: message queues. It is similar to the mailbox, and is used for the transmission of the task see message, but its supported message size is specified by the user and can exceed 4 bytes.
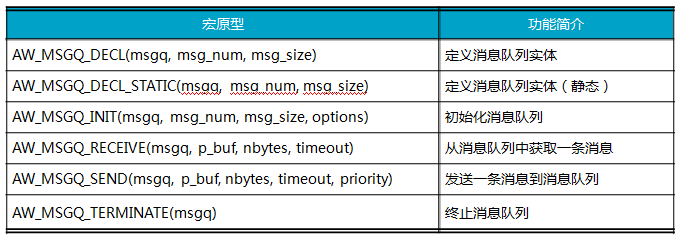
The message queue can store multiple messages. The task of sending messages is responsible for sending messages to the queue. The task of receiving messages is responsible for extracting messages from the queue. AWorks provides several macros for using the message queue. The prototype of the macro is shown in Table 10.9.
Table 10.9 Message Queue Related Macros (aw_msgq.h)
Define the message queue entity
AW_MSGQ_DECL() and
The AW_MSGQ_DECL_STATIC() macro is used to define a message queue entity, allocating necessary memory space for the message queue, including space for storing messages. Their prototype is:

Among them, the parameter msgq is the identification name of the message queue entity. Msg_num and msg_size are used to allocate space for storing messages, msg_num indicates the maximum number of messages, and msg_size indicates the size (bytes) of each message. The total memory size for storing messages is: msg_num×msg_size.
The difference between the two macros is that AW_MSGQ_DECL_STATIC() uses the static keyword when defining the memory required for the message queue. In this way, the scope of the message queue entity can be confined within the module (inside the file) to avoid the module. The conflict between the message queue naming, at the same time, you can also use this macro to define the message queue entity within the function.
If AW_MSGQ_DECL() is used to define a message queue entity with the identity msgq_test, the maximum number of messages is 10, each message is an int type data, and the size of the message is 4 bytes (in 32-bit platform). The program is detailed in Listing 10.63.
Listing 10.63 Sample Program for Defining Message Queue Entities

In general, when each message is an int data type, its size is best represented by sizeof. For an example program, see Listing 10.64.
Listing 10.64 Sample Program for Defining Message Queue Entities
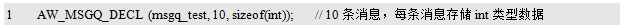
When you use AW_MSGQ_DECL() to define the message queue entity, you can embed the message queue entity in another data structure, as shown in Listing 10.65.
Listing 10.65 Embed Message Queue Entity in Structure

You can also use AW_MSGQ_DECL_STATIC() to define a message queue entity with the identifier msgq_test. For an example program, see Listing 10.66.
Listing 10.66. Sample program for defining message queue entities (static)

2. Initialize the message queue
After defining the message queue entity, you must use
AW_MSGQ_INIT() can only be used after initialization. Its prototype is:
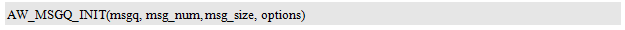
Where msgq is from AW_MSGQ_DECL() or
Message queue defined by AW_MSGQ_DECL_STATIC(). Msg_num indicates the number of messages that the message queue can store. Its value must be the same as the msg_num when the message queue entity is defined. Msg_size indicates the size (in bytes) of each message, and its value must be the same as the msg_size when defining the message queue entity.
Options is the option of the message queue, which determines the queuing mode of the tasks that are blocked in this message queue (wait messages) and can be queued according to the task priority or first-in, first-out order. Their corresponding macros are detailed in Table 10.10.
Table 10.10 Message Queue Initialization Option Macro (aw_msgq.h)

Note that the three types of semaphores are described earlier. In initialization, the queuing mode of tasks blocked by semaphores can also be specified by options. The queuing methods are divided into two methods: priority and first-in first-out. Their corresponding macro names are AW_SEM_Q_PRIORITY and AW_SEM_Q_FIFO. Unlike the naming of message queues, they cannot be mixed.
Usually, the queue mode is selected according to the priority queue. The sample program for initializing the message queue is detailed in the program listing 10.67.
Listing 10.67 Sample program for initializing a message queue
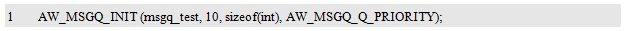
AW_MSGQ_INIT() is used to initialize a message queue entity. After initialization, it will return the ID of the message queue, whose type is aw_msgq_id_t. Define a variable of this type to save the returned ID as follows:

The specific definition of aw_msgq_id_t does not need to be concerned by the user. The ID can be used as a parameter of other message queue related interface functions introduced later to specify the message queue to be operated. In particular, if the value of the return ID is NULL, the initialization failed. In general, if there is no special requirement, the ID will not be used and the ID may not be saved.
3. Get a message from the message queue
The macro prototype for getting a message from the message queue is:
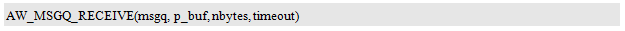
Where msgq is from AW_MSGQ_DECL() or
Message queue defined by AW_MSGQ_DECL_STATIC(). P_buf points to the buffer used to save the message. After the message is successfully obtained, it is stored in the buffer pointed to by p_buf. Nbytes specifies the size of the buffer, the buffer size must be able to hold a message, its value must not be less than the length of a message specified when the message queue entity is defined, usually, nbytes and the length of a message is equal, for example, msgq_test The length of the message in the 4 bytes, nbytes value is also 4, that is, the size of the buffer pointed to by p_buf is 4 bytes. Timeout specifies the timeout period. The return value of this macro is the standard error number of type aw_err_t. Note that since the interrupt service routine cannot be blocked, this function is prohibited from calling during interrupts.
If the message queue is not empty and contains a valid message, this operation will successfully obtain a message. At the same time, the message will be deleted from the message queue, and the number of valid messages is decremented by one. At this point, the return value of AW_MSGQ_RECEIVE() is: AW_OK.
If the message queue is empty and there is no valid message, the message cannot be acquired immediately. The specific behavior will be determined by the timeout timeout value.
(1) If the value of timeout is
AW_MSGQ_WAIT_FOREVER. The task will block this, waiting until there is a message available in the message queue, that is, other tasks or interrupts sent the message. The sample program is detailed in Listing 10.68.
Listing 10.68 Sample program for a permanent blocking wait message queue

(2) If the value of timeout is AW_MSGQ_NO_WAIT. Then the task will not be blocked, immediately return, but will not successfully get the message, this time, AW_MSGQ_RECEIVE () return value is: -AW_EAGAIN (indicating the current resource is invalid, need to retry). The sample program is detailed in Listing 10.69.
Listing 10.69 Sample program without blocking the message queue

(3) If the value of tiemout is a positive integer, it indicates the longest wait time (in units of system ticks). The task will be blocked. In the timeout specified time, if a message is successfully obtained, AW_MSGQ_RECEIVE() The return value is: AW_OK; if no message is obtained within the time specified by timeout, the return value is -AW_ETIME (indicating timeout). The sample program is detailed in Listing 10.33.
Listing 10.70 Sample program with 500ms timeout waiting for message queue

Send a message to the message queue
The macro prototype for sending messages to the message queue is:

Where msgq is from AW_MSGQ_DECL() or
Message queue defined by AW_MSGQ_DECL_STATIC(). P_buf points to the message buffer to be sent. Nbytes is the size of the message buffer. The length of the message buffer must not be greater than the length of a message specified when the message queue entity is defined. Normally, nbytes is equal to the length of a message. For example, the message length in msgq_test is 4 bytes, then the value of nbytes is also 4, that is, the size of the buffer pointed to by p_buf is 4 bytes. Timeout specifies the timeout period. Priority specifies the priority of the message. The return value of this macro is the standard error number of type aw_err_t.
If the message queue is not full, the message can continue to be stored, then the message is sent successfully, and the number of valid messages in the message queue is increased by one. At this point, the return value of AW_MSGQ_SEND() is: AW_OK.
If the message queue is full and the message cannot be stored for the time being, the message cannot be successfully sent immediately. The specific behavior will be determined by the timeout timeout value.
(1) If the value of timeout is
AW_MSGQ_WAIT_FOREVER. The task will stop there and wait until the message is successfully placed in the message queue. That is, other tasks get messages from the message queue, and the message queue leaves free space. The sample program is detailed in Listing 10.71.
Listing 10.71 Sample program for a permanent blocking wait message queue
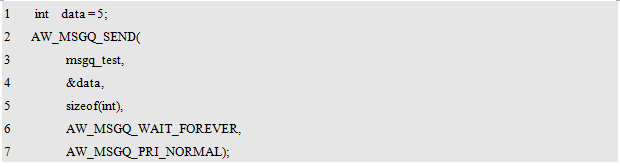
Note that the priority parameter specifies the priority of the message. There are two possible values: AW_MSGQ_PRI_NORMAL and AW_MSGQ_PRI_URGENT, which represent normal priority and emergency priority, respectively. Normally, ordinary priority is used. At this time, new messages are placed at the tail of the queue according to the organization of the queue and will be finally taken out. If emergency priority is used, new messages are placed at the head of the queue and will be fetched the next time a message is retrieved from the message queue.
(2) If the value of timeout is AW_MSGQ_NO_WAIT. The task will not be blocked, and immediately return, but will not successfully send a message. At this time, the return value of AW_MSGQ_SEND() is: -AW_EAGAIN (indicates that the current resource is invalid and needs to be retried). The sample program is detailed in Listing 10.72.
Listing 10.72 Sample program without blocking the message queue

(3) If the value of tiemout is a positive integer, it indicates the longest waiting time (in units of system ticks), the task will be blocked. In the timeout specified time, the message is successfully sent, the return of AW_MSGQ_SEND() The value is: AW_OK; if the message is not successfully sent within the time specified by timeout, the return value is -AW_ETIME (indicating timeout). The sample program is detailed in Listing 10.73.
Listing 10.73 Sample Program for Waiting Message Queue with a Timeout of 500ms

Note that in an interrupt service routine (such as a key callback function), you can use this interface to send a message to the message queue. This is an important communication method between an interrupt and a task: that is, sending a message in the interrupt and receiving it in the task Messages are processed and processed to reduce the time for interrupting service routines. However, since the interrupt cannot be blocked, the timeout flag can only be AW_MSGQ_NO_WAIT when the message is sent in the interrupt. In this application, in order to avoid message loss, the message queue should be avoided as much as possible, and the message in the message queue can be processed as soon as possible by increasing the size of the message queue and improving the priority of processing the message task.
5. Terminate the message queue
When a message queue is no longer used, the message queue can be terminated. The macro prototype is:

Where msgq is the message queue defined by AW_MSGQ_DECL() or AW_MSGQ_DECL_STATIC(). After the message queue is terminated, if there is still a task waiting for the message queue in the current system, any task waiting for the message queue will be unblocked, and -AW_ENXIO (indicating that the resource no longer exists), see the example for the program Listing 10.74.
Listing 10.74 Example procedure for terminating a message queue

In Listing 10.62, dynamic memory allocation is used to manage message storage space. To avoid dynamic memory allocation, a message queue can be used, and the length of each message is defined as 8 to store the key code and key state. The sample program is detailed in Listing 10.75.
Listing 10.75 Message Queue Usage Example Program




This program implements the same functions as the program shown in Listing 10.62 using mailboxes and message queues, respectively. The message queue avoids the use of dynamic memory allocation. When the message queue entity is defined, static memory allocation is completed. Avoid the disadvantages of using dynamic memory allocation. However, when using message queues, if the defined capacity is too large, unnecessary memory waste may result.
In addition, mailboxes and message queues send messages in different ways. For mailboxes, only the first address of the message is sent. After receiving the address, the receiver directly takes the corresponding message from the address. In this way, the message is delivered. high efficiency.
But for the message queue, when sending a message, the entire message content (such as key code and key state) is copied into the buffer of the message queue. When the message is received, the message stored in the message queue buffer is completely copied to the message queue. In the user buffer. It can be seen that there is a complete copy process of two message contents in one message transmission. This transmission method is inefficient, especially for a large message.
Therefore, it is recommended that when a message is large, the mailbox is used; when a message is small, the effect of the copy of the message on performance is weak, and the use of the message queue is more convenient and faster.
When using a mailbox, memory fragmentation, memory leaks, and allocation efficiency issues are avoided in order to avoid the use of conventional dynamic memory allocation methods. The static memory pool management technology provided by AWorks can be used to set the size of each allocated memory to a fixed value in order to avoid memory fragmentation and distribution efficiency. Memory pool management techniques are described in detail in the "Memory Management" section.
10.5 Spin Lock
Mutual exclusion semaphores are used for mutually exclusive access to shared resources between tasks. When a task acquires mutually exclusive semaphores, if the mutex semaphore is invalid and needs to wait, the task will actively release the CPU. The kernel scheduler then schedules the CPU. To perform other tasks, when the mutex semaphore recovers, re-schedule the CPU to continue the previous task. In this way, during the time the task waits for the mutex semaphore to be valid, the CPU can be fully utilized to handle other tasks.
However, the scheduling process requires a certain amount of time. In some cases, the access to shared resources may be very simple, and the CPU consumption time is very short. In other words, a task occupies a very short time for sharing resources, and it obtains mutually exclusive semaphores. Will be released soon. In this case, when a task acquires a mutex semaphore, even if the current semaphore is invalid, it means that the semaphore will be quickly released and become valid. If the task releases the CPU at this time and executes the task scheduling, it is very likely that during the task scheduling process, the semaphore is released, and the system has to re-schedule the CPU after the scheduling is finished, which makes the system spend on task scheduling. Too much time cost. In this case, the task does not release the CPU will be a better choice, can improve the efficiency of task execution.
AWorks provides a spin lock. The so-called "spin" is a "self-polling check". When a spin lock is acquired, if the spin lock is in an invalid (locked) state, the CPU will not be released but the wheel. Ask to check the spin lock until the spin lock is released (unlocked). After checking that the spin lock is released, the spin lock is acquired immediately to make it into a locked state, and then the access to the shared resource is quickly completed as soon as possible. After the access is completed, the spin lock is released.
Since when the spin lock is not available, the task will always check the status of the spin lock until it is available without releasing the CPU. The CPU does not do any other effective work during the polling wait. Therefore, only the shared resources occupy very short time. The use of spin locks is only reasonable. Otherwise, mutexes should be used. It is important to note that spin locks do not support recursive use.
AWorks provides a common interface for using spin locks. The prototype of the interface is shown in Table 10.11.
Table 10.11 Spin Lock Common Interface (aw_spinlock.h)

In AWorks, spin locks can be used in interrupts, so in the interface naming, there is an "isr" keyword. The reason why it can be used in an interrupt is that when a spin lock is acquired, the total interrupt is closed, the spin lock is released, and then the total interrupt is turned on, so that when accessing the shared resources protected by the spin lock, the CPU can be monopolized. Ensure that it will not be interrupted interrupted. Otherwise, if the task is interrupted when acquiring the spin lock has not been released, acquiring the spin lock again in the interrupt context will result in a "deadlock": the task does not release the spin lock, the interrupt can only wait; interrupt occupied CPU, the task can only continue execution after waiting for the end of the interrupt to release the spin lock.
In other words, in AWorks, spin locks can be used in interrupts. Tasks and interrupts are mutually exclusive to shared resources. When a task accesses shared resources, the interrupts are closed to achieve mutual exclusion.
1. 定义自旋é”实体
在使用自旋é”å‰ï¼Œå¿…须先使用aw_spinlock_isr_t类型定义自旋é”实体,该类型在aw_spinlock.hä¸å®šä¹‰ï¼Œå…·ä½“ç±»åž‹çš„å®šä¹‰ç”¨æˆ·æ— éœ€å…³å¿ƒï¼Œä»…éœ€ä½¿ç”¨è¯¥ç±»åž‹å®šä¹‰è‡ªæ—‹é”实体,å³ï¼š

其地å€å³å¯ä½œä¸ºå„个接å£ä¸p_lockå‚数的实å‚ä¼ é€’ï¼Œè¡¨ç¤ºå…·ä½“è¦æ“作的自旋é”。
2. åˆå§‹åŒ–自旋é”
定义自旋é”实体åŽï¼Œå¿…须使用该接å£åˆå§‹åŒ–åŽæ‰èƒ½ä½¿ç”¨ã€‚其原型为:

å…¶ä¸ï¼Œp_lock指å‘å¾…åˆå§‹åŒ–的自旋é”。flags为自旋é”çš„æ ‡å¿—ï¼Œå½“å‰æ— 任何å¯ç”¨æ ‡å¿—,该值需设置为0。åˆå§‹åŒ–自旋é”的范例程åºè¯¦è§ç¨‹åºæ¸…å•10.76。
程åºæ¸…å•10.76 åˆå§‹åŒ–自旋é”

3. 获å–自旋é”
获å–自旋é”的函数原型为:
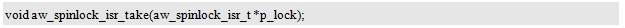
å…¶ä¸ï¼Œp_lock指å‘需è¦èŽ·å–的自旋é”。若自旋é”有效,则获å–æˆåŠŸï¼Œå¹¶å°†è‡ªæ—‹é”è®¾ç½®ä¸ºæ— æ•ˆçŠ¶æ€ï¼›è‹¥è‡ªæ—‹é”æ— æ•ˆï¼Œåˆ™ä¼šè½®è¯¢ç‰å¾…(ä¸ä¼šåƒäº’斥信å·é‡é‚£æ ·é‡Šæ”¾CPU),直到自旋é”有效(å 用该é”的任务释放自旋é”)åŽè¿”回。该接å£å¯ä»¥åœ¨ä¸æ–上下文ä¸ä½¿ç”¨ã€‚获å–自旋é”的范例程åºè¯¦è§ç¨‹åºæ¸…å•10.77。
程åºæ¸…å•10.77 获å–自旋é”

4. 释放自旋é”
释放自旋é”的函数原型为:
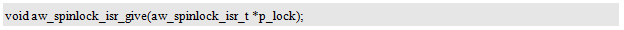
å…¶ä¸ï¼Œp_lock指å‘需è¦é‡Šæ”¾çš„自旋é”。自旋é”的获å–和释放æ“作应该æˆå¯¹å‡ºçŽ°ï¼Œå³åœ¨ä¸€ä¸ªä»»åŠ¡ï¼ˆæˆ–ä¸æ–上下文)ä¸ï¼Œå…ˆèŽ·å–自旋é”,å†è®¿é—®ç”±è¯¥è‡ªæ—‹é”ä¿æŠ¤çš„共享资æºï¼Œè®¿é—®ç»“æŸåŽé‡Šæ”¾è‡ªæ—‹é”。ä¸å¯ä¸€ä¸ªä»»åŠ¡ï¼ˆæˆ–ä¸æ–上下文)仅获å–自旋é”,å¦ä¸€ä¸ªä»»åŠ¡ï¼ˆæˆ–ä¸æ–上下文)仅释放自旋é”。释放自旋é”的范例程åºè¯¦è§ç¨‹åºæ¸…å•10.78。
程åºæ¸…å•10.78 释放自旋é”

在互斥信å·é‡çš„范例程åºä¸ï¼ˆè¯¦è§ç¨‹åºæ¸…å•10.25),使用了两个任务互斥访问共享资æºï¼ˆè°ƒè¯•ä¸²å£ï¼‰è¿›è¡Œäº†ä¸¾ä¾‹è¯´æ˜Žï¼Œç”±äºŽè°ƒè¯•ä¸²å£è¾“出信æ¯çš„速度慢,输出一æ¡å—符串信æ¯è€—æ—¶å¾€å¾€åœ¨æ¯«ç§’çº§åˆ«ï¼Œå› æ¤ï¼Œè¿™ç§æƒ…况下,使用自旋é”是ä¸åˆé€‚的。一般æ¥è®²ï¼Œæ“作硬件设备都ä¸å»ºè®®ä½¿ç”¨è‡ªæ—‹é”,自旋é”往往用于互斥访问类似于全局å˜é‡çš„共享资æºã€‚
例如,有两个任务task1å’Œtask2。在task1ä¸ï¼Œæ¯éš”50ms对全局å˜é‡è¿›è¡ŒåŠ 1æ“作,在task2ä¸ï¼Œæ£€æŸ¥å…¨å±€å˜é‡çš„值,若达到10,则将全局å˜é‡çš„值é‡ç½®ä¸º0,并翻转一次LED。
由于两个任务å‡éœ€å¯¹å…¨å±€å˜é‡è¿›è¡Œæ“作,为了é¿å…冲çªï¼Œéœ€è¦ä¸¤ä¸ªä»»åŠ¡äº’斥访问该全局å˜é‡ï¼Œæ˜¾ç„¶ï¼ŒåŠ 值æ“作是éžå¸¸å¿«çš„,å 用时间æžçŸï¼Œå¯ä»¥ä½¿ç”¨è‡ªæ—‹é”实现互斥访问,范例程åºè¯¦è§ç¨‹åºæ¸…å•10.79。
程åºæ¸…å•10.79 自旋é”使用范例程åº



1200 Puffs Disposable ecig have a completely enclosed design, reducing the need for charging and replacing cartridges. The no-charge design also reduces the occurrence of faults. It is understood that with rechargeable e-cigarettes, each cartridge needs to be charged at least once and the battery efficiency is extremely low, while the design of disposable ecig can solve this problem very well.
1200 Puff E-Cigarette,1200 Puff E-Cigarette For Sale,Best 1500 Puff E-Cigarette,Best 1200 Puff E-Cigarette For Sale
Shenzhen E-wisdom Network Technology Co., Ltd. , https://www.healthy-cigarettes.com